Convertir imagenes escaneadas a word para editarlas conSoftware OCR o reconocimiento óptico de caracteres OCR. Mejores OCR. Los mejroes softwares OCR.
El reconocimiento óptico de caracteres (ROC), generalmente conocido como reconocimiento de caracteres y expresado con frecuencia con la sigla OCR (del inglés Optical Character Recognition),
es un proceso dirigido a la digitalización de textos, los cuales
identifican automáticamente a partir de una imagen símbolos o caracteres
que pertenecen a un determinado alfabeto, para luego almacenarlos en
forma de datos. Así podremos interactuar con estos mediante un programa
de edición de texto o similar.
En los últimos años la digitalización de la información (textos,
imágenes, sonido, etcétera) ha devenido un punto de interés para la
sociedad. En el caso concreto de los textos, existen y se generan
continuamente grandes cantidades de información escrita, tipográfica o
manuscrita en todo tipo de soportes. En este contexto, poder automatizar
la introducción de caracteres evitando la entrada por teclado implica
un importante ahorro de recursos humanos y un aumento de la
productividad, al mismo tiempo que se mantiene, o hasta se mejora, la
calidad de muchos servicios.
OCR, conocido en español como ROC (reconocimiento óptico de
caracteres), es un proceso mediante el cual, a partir de un texto
digitalizado, se pueden identificar las letras, símbolos y caracteres
para almacenarlos en forma de texto y poder utilizarlos, por ejemplo, en
un procesador de textos como Word.
Gracias a los programas OCR,
en lugar de tener que transcribir un documento completo, simplemente
escaneando o digitalizando las páginas vamos a poder extraer de ellas
todo el texto para insertarlo, como hemos dicho, en un procesador de
textos como Word o cualquier otro programa similar. Aunque el resultado
no suele ser exacto al 100%, sí suele ser bastante preciso y, una vez
digitalizado y extraído el texto, bastará con una sencilla revisión
superficial para corregir cualquier error de reconocimiento de
caracteres y poder así guardar nuestro documento en el ordenador en modo
de texto.
Existen varias aplicaciones OCR para extraer texto de imágenes e
importarlo en un procesador. A continuación, vamos a ver las más
conocidas y utilizadas.
ABBYY FineReader, uno de los programas OCR más completos
ABBYY FineReader es una aplicación que nos permite
reconocer todos los caracteres de una imagen o un documento PDF,
extraerlos y permitirnos copiarlos y trabajar con ellos como si fueran
texto plano. Esta es una de las herramientas más efectivas, con una tasa
de acierto muy elevada, y compatible con más de 190 lenguajes
diferentes. Además, se integra perfectamente con Microsoft Word de
manera que, si escaneamos un documento, automáticamente podamos tenerlo
en forma de texto en la herramienta de Microsoft.
Aunque este es, probablemente, el programa más eficaz en este
aspecto, el principal problema es que es de pago, y no precisamente
barato (200 euros la versión más limitada en funciones), por lo que si
estamos buscando un programa que nos permite convertir nuestros escaneos
a texto, podemos probar cualquiera de las siguientes alternativas
gratuitas.
Tesseract, una librería OCR 100% JavaScript
Esta librería OCR empezó sus andadas en 1995 y, desde entonces, ha
seguido creciendo y actualizándose hasta ser una de las mejores
herramientas de reconocimiento digital de caracteres dentro del ámbito
gratuito y OpenSource. Esta aplicación puede resultar un poco complicada
de utilizar ya que su uso debe hacerse desde terminal o desde una
ventana de CMD, sin embargo, los comandos son muy sencillos y el
resultado que nos ofrece es excelente a nivel de precisión.
Podemos encontrar más información sobre él, una guía de instalación y uso y su descarga desde su página principal de GitHub. Esta aplicación está disponible para Windows, Linux y macOS.
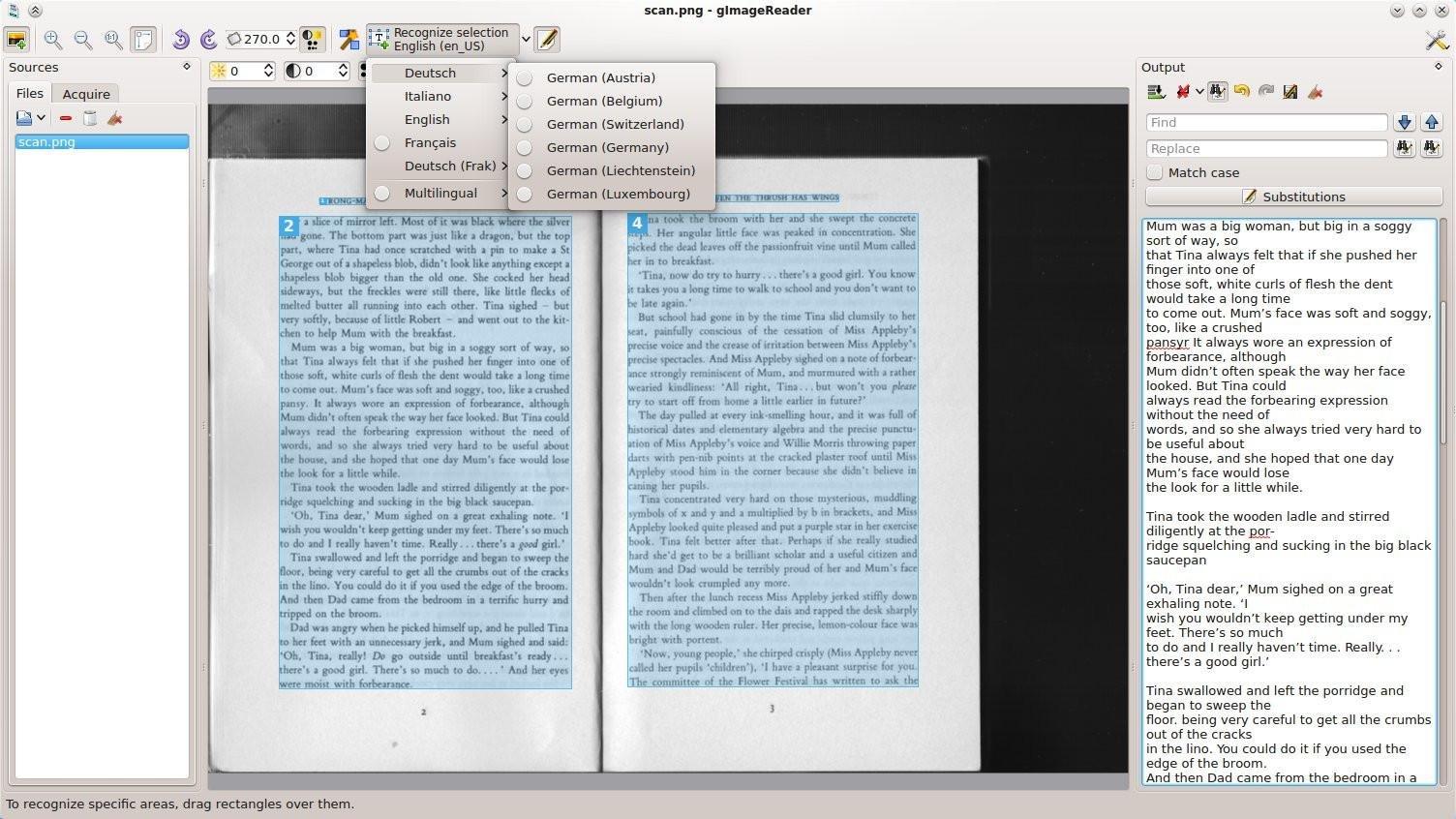
GImageReader, un frontend para Tesseract
En el punto anterior hemos hablado de la librería Tesseract escrita
en JavaScripy y dijimos que su principal inconveniente es que debe
utilizarse desde un terminal.
GImageReader es un frontend, o una interfaz, que
utiliza esta librería y que nos permite hacer uso de las funciones de
reconocimiento de una forma muy sencilla e intuitiva. Gracias a esta
herramienta, los usuarios que no se atrevan a usar Tesseract con
comandos podrán utilizar cómodamente la librería desde una ventana con
teclado y ratón.
Esta herramienta está disponible para Windows y Linux, y podemos descargarla desde el siguiente enlace.
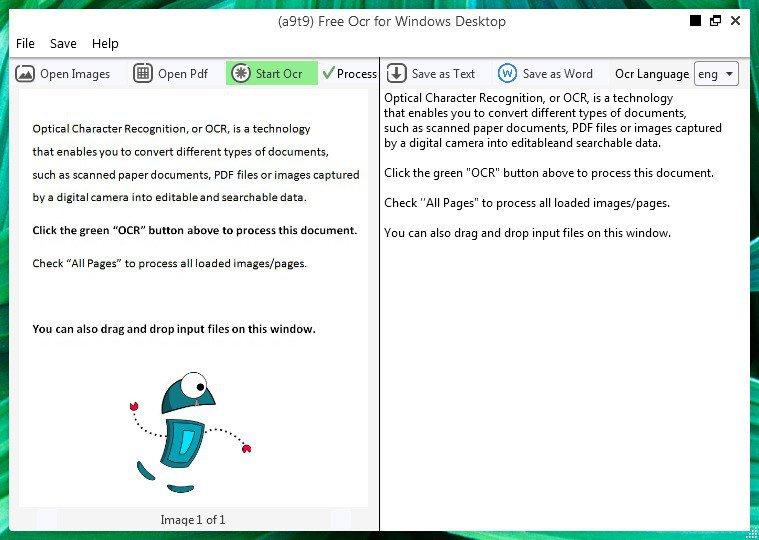
(a9t9) Free OCR Software
(a9t9) Free OCR Software es una alternativa más,
también de código abierto, a las aplicaciones de reconocimiento de
caracteres anteriores. Esta opción cuenta también con un alto porcentaje
de éxito y, además, puede ejecutarse directamente desde el navegador
sin necesidad de instalar ningún software adicional.
Podemos utilizar esta herramienta directamente desde nuestro navegador desde su página web principal.
Si queremos, también podemos descargar un cliente gratuito desde la
Windows Store (para Windows 8 y Windows 10) y una extensión para Google
Chrome.
Free OCR to Word, una alternativa más gratuita
Aunque nos salimos del ámbito OpenSource, no queríamos terminar sin hablar de Free OCR to Word.
Esta aplicación nos permite reconocer los caracteres de distintos
formatos de archivos, como JPG, JPEG, PSD, PNG, GIF, TIFF y BMP, entre
otros, e importarlos directamente a un documento de Word totalmente
editable de manera que evitemos la tediosa tarea de reescribir estos
documentos.

No hay comentarios:
Publicar un comentario